











山東迅優傳媒有限公司是一家以網站建設、網站優化、微信開發、系統開發、網絡營銷、電子商務咨詢為主的互聯網高科技公司,是專業的互聯網+平臺定制、新舊動能轉換軟件服務提供商。迅優擁有一批具有豐富設計和開發經驗的高素質、高學歷人才,同時擁有業內知名的網絡營銷、搜索引擎優化團隊。
《移動搜索建站優化白皮書》百度發布--網站優化
時間:2017-12-31 17:50 來源:山東迅優傳媒 作者:admin 點擊:3570次
3??網站優化
3.1??抓取友好性
關于抓取的優先級,在此重點強調:
√?網站更新頻率:經常更新高價值的站點,優先抓取;
√?受歡迎程度:用戶體驗好的站點,優先抓取;
√?優質入口:優質站點內鏈接,優先抓取;
√?歷史的抓取效果越好,越優先抓取;
√?服務器穩定,優先抓取;
√?安全記錄優質的網站,優先抓取;
順暢穩定的抓取是網站獲得搜索用戶、搜索流量的重要前提,影響抓取的關鍵因素,站長可以通過本章節了解。
3.1.1??URL規范
網站的URL如何設置,可參考2.3.1中的URL設置規范
3.1.1.1??參數
URL中的參數放置,需遵循兩個要點:
√?參數不能太復雜;
√?不要用無效參數,無效參數會導致頁面識別問題,頁面內容最終無法在搜索展示
另外,很多站長利用參數(對搜索引擎和頁面內容而言參數無效)統計站點訪問行為,這里強調下,盡量不要出現這種形式資源,例如:
https://www.test.com/deal/w00tb7cyv.html?s=a67b0e875ae58a14e3fcc460422032d3
或者:
http://nmtp.test.com/;NTESnmtpSI=029FF574C4739E1D0A45C9C90D656226.hzayq-nmt07.server.163.org-8010#/app/others/details?editId=&articleId=578543&articleType=0&from=sight
?
3.1.2??鏈接發現
3.1.2.1??百度蜘蛛
很多站長會咨詢如何判斷百度移動蜘蛛,這里推薦一種方法,只需兩步,正確識別百度蜘蛛:
查看UA
如果UA都不對,可以直接判斷非百度搜索的蜘蛛,目前對外公布過的UA是:
移動UA 1:
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,likeGecko)?Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0;+http://www.baidu.com/?search/?spider.html)
移動UA 2:
Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 likeMac OS X) AppleWebKit/601.1.46?(KHTML, like Gecko) Version/9.0 Mobile/13B143Safari/601.1 (compatible; Baiduspider-render/2.0;?+http://www.baidu.com/search/spider.html)
PC UA 1:
Mozilla/5.0 (compatible; Baiduspider/2.0;+http://www.baidu.com/search/spider.html)
PC UA 2:
Mozilla/5.0(compatible;Baiduspider-render/2.0;+http://www.baidu.com/search/?spider.html)
反查IP
站長可以通過DNS反查IP的方式判斷某只蜘蛛是否來自百度搜索引擎。根據平臺不同驗證方法不同,如Linux/Windows/OS三種平臺下的驗證方法分別如下:
在Linux平臺下,可以使用hostip命令反解IP來判斷是否來自百度蜘蛛的抓取。百度蜘蛛的hostname以*.baidu.com格式命名,非*.baidu.com即為冒充。

這里需要再提出一點,建議使用DNS更換為8.8.8.8后進行nslookup反向解析,否則很容易出現無返回或返回錯誤的問題。
在Windows平臺下,可以使用nslookup ip命令反解IP來判斷是否來自百度蜘蛛的抓取。打開命令處理器輸入nslookup?xxx.xxx.xxx.xxx(IP地址)就能解析IP,來判斷是否來自百度蜘蛛的抓取,百度蜘蛛的hostname以*.baidu.com格式命名,非*.baidu.com即為冒充。
在Mac?OS平臺下,網站可以使用dig命令反解IP來判斷是否來自百度蜘蛛的抓取。打開命令處理器輸入dig?xxx.xxx.xxx.xxx(IP地址)就能解析IP,來判斷是否來自百度蜘蛛的抓取,百度蜘蛛的hostname以*.baidu.com的格式命名,非*.baidu.com即為冒充。
3.1.2.2??鏈接提交
鏈接提交工具是網站主動向百度搜索推送數據的工具,網站使用鏈接提交可縮短爬蟲發現網站鏈接時間,目前鏈接提交工具支持四種方式提交:
√?主動推送:是最為快速的提交方式,建議將站點當天新產出鏈接立即通過此方式推送給百度,以保證新鏈接可以及時被百度抓取;
√?Sitemap:網站可定期將網站鏈接放到Sitemap中,然后將Sitemap提交給百度。百度會周期性的抓取檢查提交的Sitemap,對其中的鏈接進行處理,但抓取速度慢于主動推送;
√?手工提交:如果不想通過程序提交,那么可以采用此種方式,手動將鏈接提交給百度;
√?自動推送:是輕量級鏈接提交組件,將自動推送的JS代碼放置在站點每一個頁面源代碼中,當頁面被訪問時,頁面鏈接會自動推送給百度,有利于新頁面更快被百度發現。
簡單來說:建議有新聞屬性站點,使用主動推送進行數據提交;新驗證平臺站點,或內容無時效性要求站點,可以使用Sitemap將網站全部內容使用Sitemap提交;技術能力弱,或網站內容較少的站點,可使用手工提交方式進行數據提交;最后,還可以使用插件方式,自動推送方式給百度提交數據。
?
3.1.3??網頁抓取
3.1.3.1??訪問速度
關于移動頁面的訪問速度,百度搜索資源平臺(原百度站長平臺)已于2017年10月推出過閃電算法,針對頁面首頁的打開速度給予策略支持。閃電算法中指出,移動搜索頁面首屏加載時間將影響搜索排名。移動網頁首屏加載時間在2秒之內的,在移動搜索下將獲得提升頁面評價優待,獲得流量傾斜;同時,在移動搜索頁面首屏加載非常慢(3秒及以上)的網頁將會被打壓。
對于頁面訪問速度的提速,這里也給到幾點建議:
資源加載:
√?將同類型資源在服務器端壓縮合并,減少網絡請求次數和資源體積;?
√?引用通用資源,充分利用瀏覽器緩存;?
√?使用CDN加速,將用戶的請求定向到最合適的緩存服務器上;?
√?非首屏圖片類加載,將網絡帶寬留給首屏請求。
頁面渲染:
√?將CSS樣式寫在頭部樣式表中,減少由CSS文件網絡請求造成的渲染阻塞;
√?將JavaScript放到文檔末尾,或使用異步方式加載,避免JS執行阻塞渲染;?
√?對非文字元素(如圖片,視頻)指定寬高,避免瀏覽器重排重繪;
希望廣大站長持續關注頁面加載速度體驗,視網站自身情況,參照建議自行優化頁面,或使用通用的加速解決方案(如MIP),不斷優化頁面首屏加載時間。
了解MIP-移動網頁加速器可參考:https://www.mipengine.org/
?
3.1.3.2??返回碼
HTTP狀態碼是用以表示網頁服務器HTTP響應狀態的3位數字代碼。各位站長在平時維護網站過程中,可能會在站長工具后臺抓取異常里面或者服務器日志里看到各種各樣的響應狀態碼,有些甚至會影響網站的SEO效果,例如重點強調網頁404設置,百度搜索資源平臺(原百度站長平臺)中部分工具如死鏈提交,需要網站把內容死鏈后進行提交,這里要求設置必須是404。
下面為大家整理了一些常見的HTTP狀態碼:
301:(永久移動)請求的網頁已被永久移動到新位置。服務器返回此響應(作為對GET或HEAD請求的響應)時,會自動將請求者轉到新位置。
302:(臨時移動)服務器目前正從不同位置的網頁響應請求,但請求者應繼續使用原有位置來進行以后的請求。此代碼與響應GET和HEAD請求的301代碼類似,會自動將請求者轉到不同的位置。
這里強調301與302的區別:
301/302的關鍵區別在于:這個資源是否存在/有效;
301指資源還在,只是換了一個位置,返回的是新位置的內容;
302指資源暫時失效,返回的是一個臨時的代替頁(例如鏡像資源、首頁、404頁面)上。注意如果永久失效應當使用404。
有時站長認為百度對302不友好,可能是誤用了302處理仍然有效的資源;
?400:(錯誤請求)服務器不理解請求的語法;
403:(已禁止)服務器已經理解請求,但是拒絕執行它;
404:(未找到)服務器找不到請求的網頁;
這里不得不提的一點,很多站長想自定義404頁面,需要做到確保蜘蛛訪問時返回狀態碼為404,若因為404頁面跳轉時設置不當,返回了200狀態碼,則容易被搜索引擎認為網站上出現了大量重復頁面,從而對網站評價造成影響;
500:(服務器內部錯誤)服務器遇到錯誤,無法完成請求;
502:(錯誤網關)服務器作為網關或代理,從上游服務器收到了無效的響應;
503:(服務不可用)目前無法使用服務器(由于超載或進行停機維護)。通常,這只是一種暫時的狀態;
504:(網關超時)服務器作為網關或代理,未及時從上游服務器接收請求。
?
3.1.3.3? robots
robots工具的詳細工具使用說明,細節參考4.3.4robots工具章節,關于robots的使用,僅強調以下兩點:
√?百度蜘蛛目前在robots里是不支持中文的,故網站robots文件編寫不建議使用中文字符;
√?robots文件支持UrlEncode編碼這種寫法,如:http://www.test.cn/%E7%89%B9%E6%AE%8A:%E6%B5%8F%E8%A7%88/%E7%94%9F%E6%AD%BB%E7%8B%99%E5%87%BB:%E7%99%BD%E9%93%B6%E5%8A%A0%E7%89%B9%E6%9E%97
3.1.3.4??死鏈
當網站死鏈數據累積過多,并且被展示到搜索結果頁中,對網站本身的訪問體驗和用戶轉化都起到了負面影響。另一方面,百度檢查死鏈的流程也會為網站帶來額外負擔,影響網站其他正常頁面的抓取和索引。
百度搜索資源平臺(原百度站長平臺)推出死鏈提交工具,幫助網站提交死鏈數據,死鏈提交工具使用參考4.3.2死鏈提交工具。
什么是死鏈及死鏈的標準
頁面已經無效,無法對用戶提供任何有價值信息的頁面就是死鏈接,比較常見死鏈形式共有3種,協議死鏈和內容死鏈是比較常見兩種形式,除此之外還有跳轉死鏈。
√?協議死鏈:頁面的TCP協議狀態/HTTP協議狀態明確表示的死鏈,常見的如404、403、503狀態等;
√?內容死鏈:服務器返回狀態是正常的,但內容已經變更為不存在、已刪除或需要權限等與原內容無關的信息頁面;
√?跳轉死鏈:指頁面內容已經失效,跳轉到報錯頁,首頁等行為。
?
3.1.4??訪問穩定性
訪問穩定性主要有以下幾個注意點:
DNS解析
DNS是域名解析服務器,關于DNS,這里建議中文網站盡可能使用國內大型服務商提供的DNS服務,以保證站點的穩定解析。
分享一個DNS穩定性的示例:
搜索資源平臺(原站長平臺)曾收到多個站長反饋,稱網站從百度網頁搜索消失,site發現網站數據為0。
經追查發現這些網站都使用國外某品牌的DNS服務器 *.DOMAINCONTROL.COM,此系列DNS服務器存在穩定性問題,百度蜘蛛經常解析不到IP,在百度蜘蛛看來,網站是死站點。此前也發現過多起小DNS服務商屏蔽百度蜘蛛解析請求或者國外DNS服務器不穩定的案例。因此這里建議網站,謹慎選擇DNS服務。
蜘蛛封禁
針對爬蟲的封禁會導致爬蟲認為網站不可正常訪問,進而采取對應的措施。爬蟲封禁其實分兩種,一種就是傳統的robots封禁,另一種是需要技術人員配合的IP封禁和UA封禁;而絕大多數情況下的封禁都是一些操作不當導致的誤封禁,然后在搜索引擎上的反應就是爬蟲不能正常訪問。所以針對爬蟲封禁的操作一定要慎重,即使因為訪問壓力問題要臨時封禁,也要盡快做恢復處理。
服務器負載
拋開服務器硬件問題(不可避免),絕大多數引起服務器負載過高的情況是軟件程序引起的,如程序有內存泄露,程序出core,不合理混布服務(其中一個服務消耗服務器資源過大引起服務器負載增大,影響了服務器對爬蟲訪問請求的響應。)對于提供服務的機器一定要注意服務器的負載,留足夠的buffer保證服務器具有一定的抗壓能力。
其他人為因素
人為操作不當引起訪問異常的情況是經常見到的,針對這種情況需要嚴格的制度約束,不同站點情況不一樣。需要保證每一次的升級或者操作要準確無誤。
?
3.1.5??可訪問鏈接總量
3.1.5.1??資源可窮盡
一般來說網站的內容頁面是可窮盡的,萬級別,百萬級別甚至億級別,但一定是可窮盡的。而現實中確實存在這樣一些網站,爬蟲針對這些網站進行抓取提鏈時會陷入"鏈接黑洞";通俗的講就是網站給爬蟲呈現的鏈接不可窮盡;典型的是部分網站的搜索結果頁,不同的query在不同anchor下的a標簽鏈接不一樣就導致了"鏈接黑洞"的產生,所以嚴禁URL的生成跟用戶的訪問行為或者搜索詞等因素綁定。
?
3.2??頁面解析
頁面解析,主要指網站頁面被蜘蛛抓取,會對頁面進行分析識別,稱之為頁面解析。頁面解析對網站至關重要,網站內容被抓取是網站被發現的第一步,而頁面解析,則是網站內容被識別出來的重要一環,頁面解析效果直接影響搜索引擎對網站的評價。
3.2.1??頁面元素
3.2.1.1??頁面標題
關于網頁標題,百度搜索于2017年9月推出清風算法,重點打擊網站標題作弊,引導用戶點擊,損害用戶體驗的行為;清風算法重點打擊的標題作弊情況有以下兩種:
√?文不對題,網站標題與正文有明顯不符合,誤導搜索用戶點擊,對搜索用戶造成傷害;
√?大量堆砌,網站標題中出現大量堆砌關鍵詞的情況也十分不提倡,
關于網站標題作弊的詳細解讀,參考搜索學院發布官方文檔《百度搜索內容質量白皮書——網頁標題作弊詳解》。
關于網站TDK,有以下幾種情況需要注意:("T"代表頁頭中的title元素,"D"代表頁頭中的description元素,"K"代表頁頭中的keywords元素,簡單指網站的標題、描述和摘要);
√ 百度未承諾嚴格按照title和description的內容展示標題和摘要,尤其是摘要,會根據用戶檢索的關鍵詞,自動匹配展示合適的摘要內容,讓用戶了解網頁的主要內容,影響用戶的行為決策;
√?站長會發現同一條鏈接的摘要在不同關鍵詞下是變化的,可能不會完全符合站長預期,尤其是站長在檢索框進行site語法操作時,可能會感覺摘要都比較差。但請不要擔心,畢竟絕大多數普通網民不會這樣操作。在此情況下出現不符合預期的摘要并不代表站點被懲罰;
√?還有一種情況,是網頁中的HTML代碼有誤,導致百度無法解析出摘要,所以有時大家會看到某些結果的摘要是亂碼(當然這種情況很少見),所以也請站長注意代碼規范。
3.2.1.2??主體內容
主體內容注意兩個點,一個主體內容過長(通常網頁源碼長度不能超過128k),文章過長可能會引起抓取截斷;另外一個是注意內容不能空短,空短內容也會被判斷為無價值內容。
以下分析兩個示例:
關于主體內容過長的示例分析:
某網站主體內容都是JS生成,針對用戶訪問,沒有做優化;但是網站特針對爬蟲抓取做了優化,直接將圖片進行base64編碼推送給百度,然而優化后發現內容沒有被百度展示出來;
頁面質量很好,還特意針對爬蟲做了優化,為什么內容反而無法出現在百度搜索中;
分析主要有以下原因:
√?網站針對爬蟲爬取做的優化,是直接將圖片base64編碼后放到HTML中,導致頁面長度過長,網站頁面長度達164k;
√?站點優化后將主體內容放于最后,圖片卻放于前面;
√?爬蟲抓取內容后,頁面內容過長被截斷,已抓取部分無法識別到主體內容,最終導致頁面被認定為空短而不建索引。
這樣的情況給到以下建議:
√?如站點針對爬蟲爬取做優化,建議網站源碼長度在128k之內,不要過長;
√?針對爬蟲爬取做優化,請將主體內容放于前方,避免抓取截斷造成的內容抓取不全。
關于內容空短的示例分析:
某網站反饋網站內容未被建索引,分析發現,網站抓取沒有問題,但被抓取到的頁面,都提示需要輸入驗證碼才能查看全部頁面,這類頁面被判斷為空短頁面,這類頁面在抓取后,會被判定為垃圾內容。
而且當蜘蛛對一個網站抓取后發現大面積都是低值的空短頁面時,爬蟲會認為這個站點的整體價值比較低,那么在后面的抓取流量分布上會降低,導致針對該站點的頁面更新會比較慢,進而抓取甚至建索引庫也會比較慢。
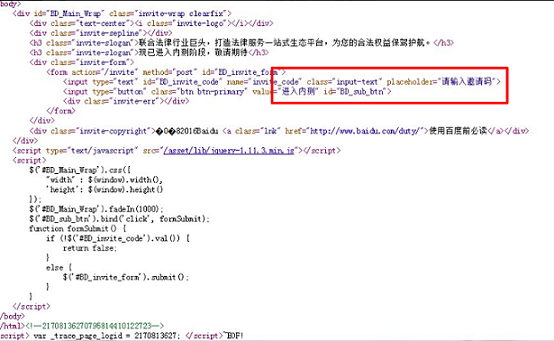
為什么會出現網站內容空短這種情況,其中一個原因是網站內容未全部搭建完成,未對外開放,但已被蜘蛛爬取發現。針對這種情況,建議網站在邀請測試階段使用robots封禁。
另外還會有些網站,設置用戶查看權限,如需用戶登陸才能查看全部內容,這樣的行為對搜索引擎也極不友好,蜘蛛無法模擬用戶登陸,僅能抓取網站已展示頁面,可能會導致抓取頁面為空短的現象。
這里再次強調,不要讓爬蟲給站點畫上不優質的標簽,對網站將產生很不好的影響。另外,移動端的H5頁面,很多都是采用JS方式加載,其實是更容易產生空短,請各位站長注意。
??
?
3.2.1.3??網頁發布時間
關于網頁發布時間,有以下幾點建議:
√?網頁內容盡可能加上產出時間,嚴格說是內容發布時間;且時間盡量全,時間格式為年-月-日?時:分:秒;
例:2017-08-12 10:23:06
√?網頁上切忌亂加時間,這樣容易造成頁面時間提取問題,或搜索引擎判斷提取時間不可信,從而降低對網頁的展現。
?
3.2.1.4??canonical標簽
canonical標簽的目的
在PC互聯網時代,canonical標簽的作用主要是用來解決由于網址形式不同內容相同而造成的內容重復問題。而在移動時代,canonical標簽被百度搜索賦予了更多的意義,在原來的作用基礎上,又起到了相同內容的移動頁和PC頁之間的關聯作用;讓移動資源更容易繼承PC資源的各種特征,從而快速生效移動網頁數據。
canonical標簽如何設置
在HTML代碼的head里添加rel="canonical",不能添加多個,否則搜索引擎會認為是無效的canonical標簽。另外需要注意href里的地址不能是死鏈,錯誤頁或者被robots封禁的頁面。
具體示例如下:
3.2.2??落地頁體驗
為提升移動搜索整體用戶體驗,提升搜索滿意度,百度搜索在2017年推出《百度移動搜索落地頁體驗白皮書——廣告篇2.0》(以下簡稱廣告白皮書)。廣告白皮書對網站移動落地頁頁面廣告內容、廣告位置、大小等做了明確要求,從而充分保證搜索用戶的瀏覽體驗。
白皮書詳情,請參考搜索學院官方文檔《百度移動搜索落地頁體驗白皮書——廣告篇2.0》
3.3??頁面價值
3.3.1??內容價值
原創文章,要求是獨立完成的創作,且沒有歪曲、篡改他人創作或者抄襲、剽竊他人創作而產生的作品,對于改編、注釋、整理他人已有創作而產生的作品要求有充分的點評、補充等增益信息。
建議原創文章在標題下方明確注明“來源:xxxx(本站站點名)”或“本站原創”之類字樣,轉載文章明確注明“來源:xxxx(轉載來源站點名)”之類字樣,不建議使用“admin”、“webmaster”、“佚名”等模糊的說法。
3.3.2??外鏈建設
通常認為,外鏈是本站點對第三方站點頁面的鏈接指向,是本站點對第三方站點頁面內容的一種認可和推薦。
站點進行外鏈建設時,建議是有真實推薦意圖,并且指向那些熟悉的、被認可的、內容相關的外部頁面;不建議推薦與本站點頁面內容無關的外鏈內容。也不建議亂推薦外鏈、交換外鏈互聯、指向作弊站的行為(這些很可能被超鏈策略反向識別成垃圾作弊站點進行打壓)。
最后,站長要及時發現和處理站點被黑的頁面。頁面被黑掉后,一般會被人為放入大量無關的,甚至作弊的外鏈在該頁面上,其目的是要瓜分站點自身權重,并以此來提高外鏈目標站點影響力。建議站長發現后,及時向搜索資源平臺(原站長平臺)提交死鏈進行刪除和屏蔽,不及時處理一定程度上會影響站點本身的權重。最好從技術上優化,提高站點安全壁壘,防范于未然。
3.3.3??內鏈建設
內鏈,描述了站點的結構,一般起到頁面內容組織和站內引導的作用;內鏈的重要意思是通過鏈接指向,告訴搜索引擎哪個頁面最為重要。
內鏈組織的時候,建議結構清晰,不要過于冗雜,另外內鏈組織的版式建議保持一致,這樣對搜索引擎超鏈分析比較友好。
與外鏈類似,建議站長善于使用nofollow標簽,既對搜索引擎友好,又可避免因垃圾link影響到站點本身的權重。
3.3.4??anchor
anchor描述:盡可能使用典型的,有真實意義的anchor。anchor描述要與超鏈接的頁面內容大致相符,避免高頻無意義anchor的使用,另外同一個URL的anchor描述種類不宜過多,anchor分布越稀疏會影響搜索排名。
(責任編輯:admin)


